Overview
Futures are an excellent way of gaining access and exposure to various asset classes. The contracts are often much more liquid than their underlyings, long- and short positions can be entered equally easy, and there is no cash changing hands involved by entering a position (we only refer here to the investment needed for being long in the cash market; of course there is margining with Futures, which also implies needs for liquidity). Nevertheless traders and researchers have to consider certain specialities of Futures which may come as a downside: one of those is clearly handling the chain of contracts over time. Questions around that could be be simple like: "What has to be done to stay invested over a medium or a long term by rolling over from one contract to the other? Other, more subtle questions are such as: "What are the implications of the price gaps between contracts? What does the gap actually mean and does it has a systematic direction ("carry")? Do we have to take care about this and how are my trading signals, backtesting, and PnL influenced?"
We will tackle the above questions in a series of two articles, where the first one will discuss and implement methods to consistently trade and analyze Futures in the light of gaps between the various contracts over time. The second article will be much more about prominent trading signals such as MACD, RSI, or Bollinger Bands. There we will also spent a decent amount of time on visualization of the differently edited time series and what the various methods mean for the actual trading signals.
The time series for our analysis will be short-, medium-, and long term German Government Bond Futures (Schatz, Bobl, Bund). With regards to our technical focus, we will utilize Python and present all the code involved to make everything outlined here easy to replicate by yourself.
Some basics about Futures trading
Futures terminology
Before we will carry out a certain methodology, we will visit some common procedures to generate a continuous time-series. For all this, there is some terminology needed, which frequently comes with Futures. For our purposes we will refer to front and back contracts, where the front contract is the first Futures due for expiry, while the back contract matures later by a particular frequency (often one or three months after the front contract). In the context of comparing the prices between two subsequent Futures, a higher price in the back contract is referred to as contango, while we speak of backwardation in case of the opposite price relationship. Another important aspect is the tick size and the tick value of a contract. Tick size refers to the smallest possible price movement and tick value is the loss or gain incurred by that movement.
Basis between subsequent Futures contracts
So first of all, we have to ask, why there is a difference in the price in subsequent Futures contracts at all? To gain an understanding of this, one way is to follow the close link between Futures contract and underlying, and at the same time acknowledge that, — given an arbitrage free world — a holding, whether in the underlying or the Futures, will yield exactly in the same payoffs for the investor. So more precisely, the cost of holding the underlying until the next respective expiration date, determines the gap between two contracts. Depending on the market, those influence factors can be repo rates, dividends, storage costs, etc.
Building a Continuous Futures contract
Available methods at a glance
Before we start implementing algorithms to come up with a Continuous Futures time-series, we will shortly discuss the most prominent techniques available in that space.
1. Splicing contracts together with no adjustments
This is the typically done already by market data providers like Bloomberg or Reuters (FGBLc1 for the spliced Bund for instance). We will (possibly) end up in a price jump on the day when contracts are switched. In case trading signals (see second article) are extracted from those series, we rely on a mix of inputs from both contracts potentially yielding a biased result as the price jump is inherited in the calculations. We also receive a distorted picture with regards to backtesting the PnL of any strategy relying on such a time series. Just imagine a MACD strategy would make you buy just before the front contract matures and sell straight after in the back contract (or the then front contract at the point in time of selling). Assuming a contango you would clearly overstate your profit.
2. Splicing contracts together with explicitly accounting for a roll over
In the above mentioned MACD strategy example, we would clearly correct the inflated PnL by selling the front contract and buying into the back contract simultaneously at or just before expiry. Afterwards, we would then sell the former back contract (being the new front contract by now) correctly reflecting the price jump in our performance measurement. But still, we are left with biased signals from strategies relying on both contracts.
3. Continuously adjusting the contracts over time ("Perpetual Method")
In a nutshell, the Perpetual Method applies weights to front and back contract over a pre-defined period of time. So to say, we trade out of the "old" contract into the "new" in a linear fashion. For instance, if we assume 5 roll over days, we do the weighting according to the following scheme:
| Contract | Day 1 | Day 2 | Day 3 | Day 4 | Day 5 |
|---|---|---|---|---|---|
Front |
80% |
60% |
40% |
20% |
0% |
Back |
20% |
40% |
60% |
80% |
100% |
Applying this method clearly improves the sudden price change introduced by switching to a new contract by smoothing the roll over according to the weighting scheme. Note that trading has also to be set up accordingly to make everything consistent.
4. Splicing contracts together with forward or backward adjustments ("Panama Adjustment")
The Panama Adjustment either adjusts the actual (forward) or the historical (backward) contracts, such that they align in a smooth fashion on expiry date. While overcoming the distortion on signal generation due to a smooth time series, we are left with biased relative price performance stemming from absolute series adjustments (the absolute gaps between contracts). This can also leads to potentially strong data trends, especially over long time horizons (with even the possibility of negative prices). However, the prior PnL or performance unit of Futures is the tick value, which still can be easily interpreted correctly, even if we would analyze a time series trending away substantially from the original Futures prices.
Determine the method of choice for a Continuous Futures with our data set
From the above discussion the Panama Adjustment as well as the Perpetual Method sound promising. We will test the two and benchmark them against simply Splicing Contracts with the already identified drawbacks. For the simple splicing we will utilize generic Thomson Reuters Eikon Futures contracts being fetched by the Python API. We will then process the observed data in Python, analyze the outcomes, and pick our method of choice.
Spliced contracts
As mentioned above, we we pick German Government Bond Futures (Schatz, Bobl, Bund) for our analysis. We collect daily OHLCV ("Open", "High", "Low", "Close", "Volume") market data for the respective securities in a dict of Pandas DataFrames. Thomson Reuters Eikon offers Continuous ("spliced together") Futures data by calling the ticker symbol (i. e. "FGBL" for the Bund) and "c1" and "c2" for the continuous front and back contract. The following code will do this for us:
import numpy as np # (1)
import pandas as pd
import eikon as ek
import configparser
config = configparser.ConfigParser() # (2)
config.read('logins.cfg')
ek.set_app_id(config['eikon']['app_id'])
def get_fut_front_back(start_date, end_date, front_perpr = ['FGBLc1', 'FGBMc1', 'FGBSc1'], # (3)
back_perpr = ['FGBLc2', 'FGBMc2', 'FGBSc2'],
fields = ['OPEN', 'LOW', 'HIGH', 'CLOSE', 'VOLUME']):
'''
Fetch daily Futures data for front and back contract and return as dict of dfs.
Pass in start and end date as 'yyyy-mm-dd'.
Front and back contracts are passed as list objects with Bund, Bobl, Schatz as pre-selection.
'''
data_dict = {}
start_date = pd.to_datetime(start_date)
end_date = pd.to_datetime(end_date)
fields = fields
for i in range(len(front_perpr)):
data_dict[front_perpr[i][0:-2]] = ek.get_timeseries([
front_perpr[i], back_perpr[i]
],
fields=fields,
start_date=str(start_date),
end_date=str(end_date),
interval='daily'
)
return data_dict
data_dict = get_fut_front_back('2017-1-1', '2017-11-17') # (4)-
Library imports
-
Setup Thomson Reuters Eikon Python API
-
Function for data retrieval
-
Write time-series to dict variable data_dict
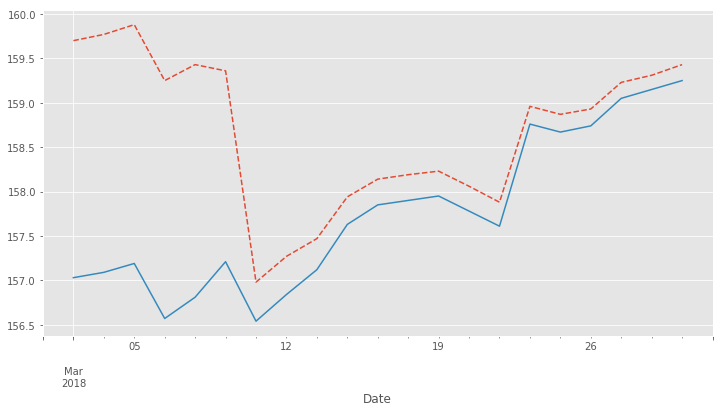
We can easily visualize the roll gap for the Bund March '18 roll with Matplotlib. Below you see the front contract ("FGBLc1", dashed red line) and the back contract ("FGBLc2", blue solid line). On the 8th, "FGBLc1" expires and therefore "FGBLc2" becomes the new "FGBLc1". That is why you see the sudden drop in the time-series.
Perpetual Method
To implement the Perpetual Method as outlined above, we define a function "get_perp_fut". The function basically takes the already fetched DataFrames consisting of spliced front and back contracts as "market_data" argument. Additionally, the rollover days and the data columns can be specified. Below is the Python representation of that function:
def get_perp_fut(market_data, expiry_dates, rollover_days=5, # (1)
data_cols=['OPEN', 'LOW', 'HIGH', 'CLOSE', 'VOLUME']):
'''
Converts a df of pairs of Futures contracts ('Front' & 'Back' ) into a continuous
time series returned as df.
Pass in market data as df.
expiry_dates takes an excel file (i.e. "Futures_Exp.xlsx")
with column A beeing the Futures name and column B being the expiry date.
No column headers.
We take European dates (dd-mm-yyyy).
'''
market_data.columns.set_levels(['Front', 'Back'], 0, inplace = True)
expiry_dates = pd.read_excel(expiry_dates, header=None, index_col=0, squeeze=1)
expiry_dates = pd.to_datetime(expiry_dates.values, dayfirst = True)
columns = pd.MultiIndex.from_tuples(tuple(zip(
['Front'] * len(data_cols) + ['Back'] * len(data_cols), data_cols * 2)
))
roll_weights = pd.DataFrame(np.zeros((len(market_data.index), 2 * len(data_cols))),
index = market_data.index, columns=columns)
decay_weights = np.repeat(np.linspace(0, 1, rollover_days + 1),
int(len(data_cols))).reshape(rollover_days + 1,
int(len(data_cols)))
for i in range(len(expiry_dates)):
roll_weights.loc[expiry_dates[i]:, 'Front'] = 1
roll_weights_target = roll_weights.iloc[
roll_weights.index.get_loc(expiry_dates[i]) - rollover_days :
roll_weights.index.get_loc(expiry_dates[i]) + 1
].index
roll_weights.loc[roll_weights_target, 'Back'] = decay_weights
roll_weights.loc[roll_weights_target, 'Front'] = 1 - decay_weights
roll_weights_target = roll_weights.iloc[
0 : roll_weights.index.get_loc(expiry_dates[0]) - rollover_days
].index
roll_weights.loc[roll_weights_target, 'Front'] = 1
weighted_fut = roll_weights * market_data
perp_fut = weighted_fut['Front'] + weighted_fut['Back'].fillna(0)
return perp_fut
for key in data_dict.copy().keys(): # (2)
data_dict['%s_perp_10' % key] = get_perp_fut(
data_dict[key], 'Gov_Futures_Exp.xlsx', rollover_days=10)
data_dict['%s_perp_40' % key] = get_perp_fut(
data_dict[key], 'Gov_Futures_Exp.xlsx', rollover_days=40)-
Function to get Perpetual Method time-series
-
Add time-series with 10 and 40 rollover days to data_dict
Probably the best way of seeing how our just created Continuous Futures performs is to visualize the outcome. Again we use Matplotlib and specify 10 and 40 days respectively as rollover period. We also include our Spliced Contracts series as benchmark.
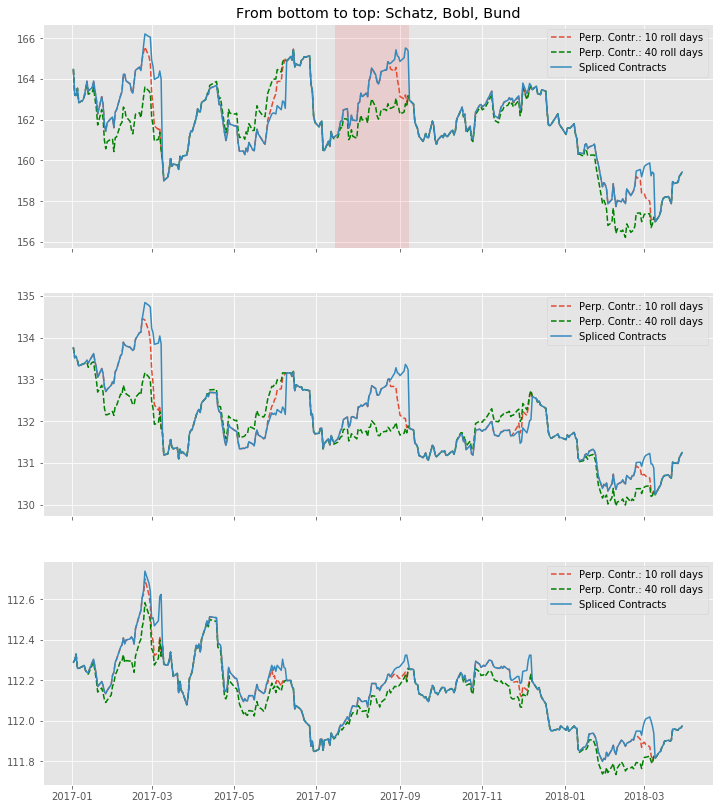
We can conclude that — given the large roll gaps especially for Bobl and Bund — , a longer roll period enhances the "smoothness" of the time-series. But still, even if we use 40 days, we amend our data in a way that is probably not a perfect fit. For instance, consider the highlighted area in the Bund chart: For 10 roll days we completely miss the daily market directions. On those 10 days, we are dragged down by the roll gap, such that we artificially create a downward trend that never really existed. If we look at the 40 roll days, we are clearly able to better capture the daily movements, but still, we are missing another element, which is the slight upward trend during the roll. To make the Perpetual Method a better fit, we would even have to lengthen the rollover further. By this we would run into other areas of trouble, namely an illiquid back contract and a hugely complex trading in case we want to do this consistently to our rollover.
Panama Method
Here we proceed basically the same like above: From our simple spliced contracts we form a smooth time series by defining a Python function doing the heavy-lifting for us. To be in line with prices in the market, we keep the most recent data unadjusted and cumulate the roll gap backwards over time. As the basis of the relevant Futures prices tend to be quite volatile just before the roll, we average the 4 trading days just before expiry. Given an absence of a particular view on price direction during roll, that makes sense to limit risks in trading, if the actual position is rolled over accordingly (we borrow a bit from the Perpetual Method here).
The code snippet below will illustrate our methodology:
def get_pan_fut(market_data, expiry_dates, # (1)
data_cols=['OPEN', 'LOW', 'HIGH', 'CLOSE', 'VOLUME']):
'''
Converts a df of pairs of Futures contracts ('Front' & 'Back' )
into a continuous time series returned as df.
Pass in market data as df.
expiry_dates takes an excel file (i.e. "Futures_Exp.xlsx")
with column A beeing the Futures name and column B being the expiry date.
No column headers. We take European dates (dd-mm-yyyy).
'''
market_data.columns.set_levels(['Front', 'Back'], 0, inplace = True)
expiry_dates = pd.read_excel(expiry_dates, header=None, index_col=0, squeeze=1)
expiry_dates = pd.to_datetime(expiry_dates.values, dayfirst = True)
pan_fut = pd.DataFrame(np.zeros((len(market_data.index), len(data_cols))), # (1)
index = market_data.index, columns=data_cols)
roll_adjustment_total = np.zeros([len(data_cols), 1])
pan_fut.iloc[pan_fut.index.get_loc(expiry_dates[-1]) + 1:] = market_data['Front'].iloc[
market_data['Front'].index.get_loc(expiry_dates[-1]) + 1:]
for i in reversed(range(len(expiry_dates))):
pan_fut.loc[expiry_dates[i]] = roll_adjustment_total.reshape(
1, len(data_cols)) + market_data['Back'].loc[expiry_dates[i]].values
roll_adjustment = market_data['Back']['CLOSE'].iloc[
market_data['Front'].index.get_loc(expiry_dates[i]) - 4:
market_data['Front'].index.get_loc(expiry_dates[i])
] - market_data['Front']['CLOSE'].iloc[
market_data['Back'].index.get_loc(expiry_dates[i]) - 4:
market_data['Back'].index.get_loc(expiry_dates[i])
]
roll_adjustment = np.repeat(roll_adjustment.values.mean(), len(data_cols) - 1)
roll_adjustment = np.append(roll_adjustment, 0)
roll_adjustment = roll_adjustment.reshape(len(data_cols), 1)
roll_adjustment_total += roll_adjustment
if i > 0:
roll_target = market_data['Front'].iloc[
market_data['Front'].index.get_loc(expiry_dates[i - 1]) + 1:
market_data['Front'].index.get_loc(expiry_dates[i])].index
roll_adjustment_target = np.tile(roll_adjustment_total, len(roll_target)).T
pan_fut.loc[roll_target] = roll_adjustment_target + market_data['Front'].loc[
roll_target]
else:
roll_target = market_data['Front'].iloc[
0:market_data['Front'].index.get_loc(expiry_dates[i])].index
roll_adjustment_target = np.tile(roll_adjustment_total, len(roll_target)).T
pan_fut.loc[roll_target] = roll_adjustment_target + market_data['Front'].loc[
roll_target]
return pan_fut
for key in data_dict.copy().keys(): # (2)
data_dict['%s_pan' % key] = get_pan_fut(data_dict[key], 'Gov_Futures_Exp.xlsx')-
Function to get Panama Method time-series
-
Add time-series to data_dict
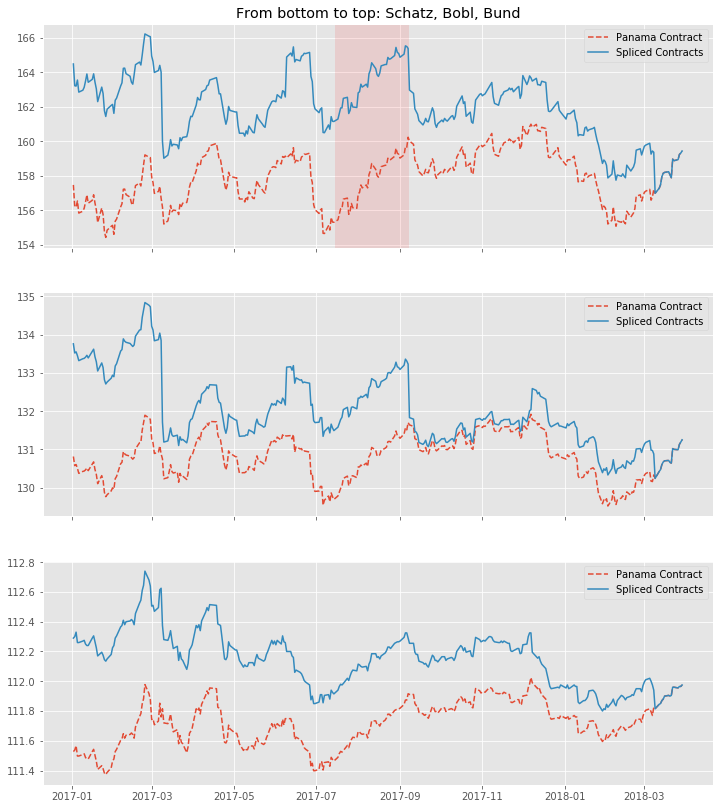
We again visualize the outcome with Matplotlib. The most encouraging point can be seen at a first glance: Even with large roll gaps, we don’t introduce some new, non existent trends into our data. Of course, we pay the price with a growing and growing divergence from the real data if we travel backwards in time. But again, this seems to be a price worth paying, if we interpret our data correctly.
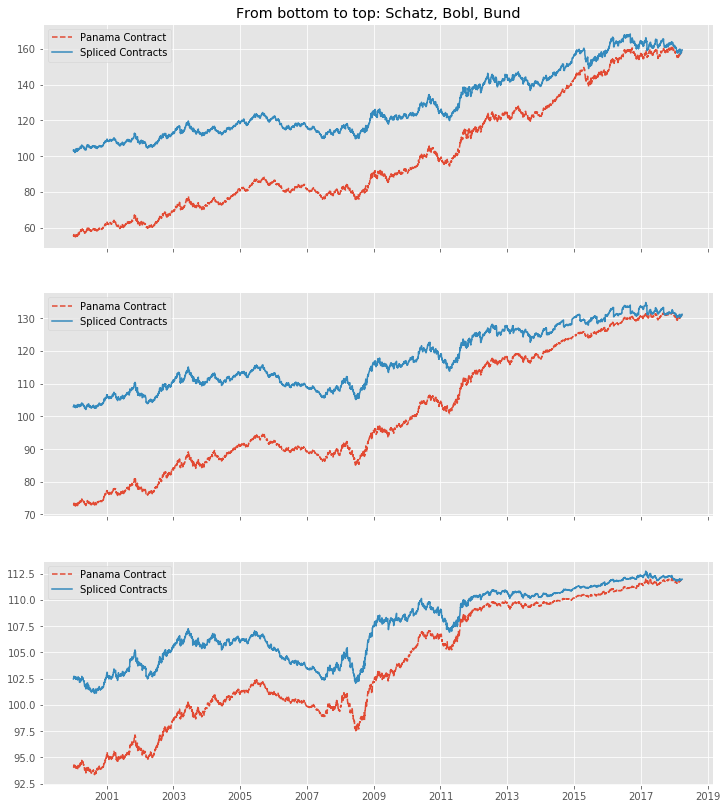
To get a better feeling of how a even longer time-series would be changed, here are our contracts with the Panama Method back as far as 2000-1-1 (a period which was almost entirely a bull market for government bonds). You can see how nice being long over that period would have been, as carry even enhances the stellar return for the buyer.
Our method of choice
With the rather large gaps between contracts in our time series, we choose the Panama Method over the Perpetual Method. This is especially significant for Bobl and Bund, while on Schatz we are a bit more relaxed towards the method, as roll gaps are not that significant.
In the next article of this series we utilize our Continuous Futures contract for generating trading signals on popular technical analysis measures. We will compare those signals to the simple Spliced Contracts benchmark. As technical analysis is a rather visual topic, we will switch from Matplotlib to a combination of the Cufflinks and Plotly libraries more suited for building charts in the trading context and nice HTML hover effects coming on top of it.
That being said, some additional remarks on our framework: There is surely further room to improve upon all this by fine tuning the methodology. One branch might be to further align trading, performance measurement and signal generation for example by switching from our vectorised approach to an event-driven approach with more granular data on intra-day basis.
Downloads
References
This is a post in the
Continuous Futures series.
Other posts in this series:
- May 26, 2018 - Continuous Futures — Construction Methods
- May 26, 2018 - Continuous Futures — Visualization & Signal Analysis